🛡️ Using GuardionAI with OpenAI Agents SDK
GuardionAI provides real-time LLM security protection and AI incident monitoring for GenAI systems and AI agents. With the OpenAI Agents SDK, you can integrate GuardionAI as both input and output guardrails in your agent pipelines. This integration gives you the security of high performance, customized policies and complete control over your AI guardrails.- Multilingual support: Enhanced capabilities across multiple languages, including spanish, portuguese, and english
- Ultra-Fast API Response: Sub-50ms API latency for real-time protection
- AI Incident Monitoring: Real-time detection, alerting and auditing for potential threats or security incidents in AI interactions
🧪 Try Integrating GuardionAI + Agents SDK in the Google Colab
Use our interactive Colab notebook experiment: 👉 Open in Google Colab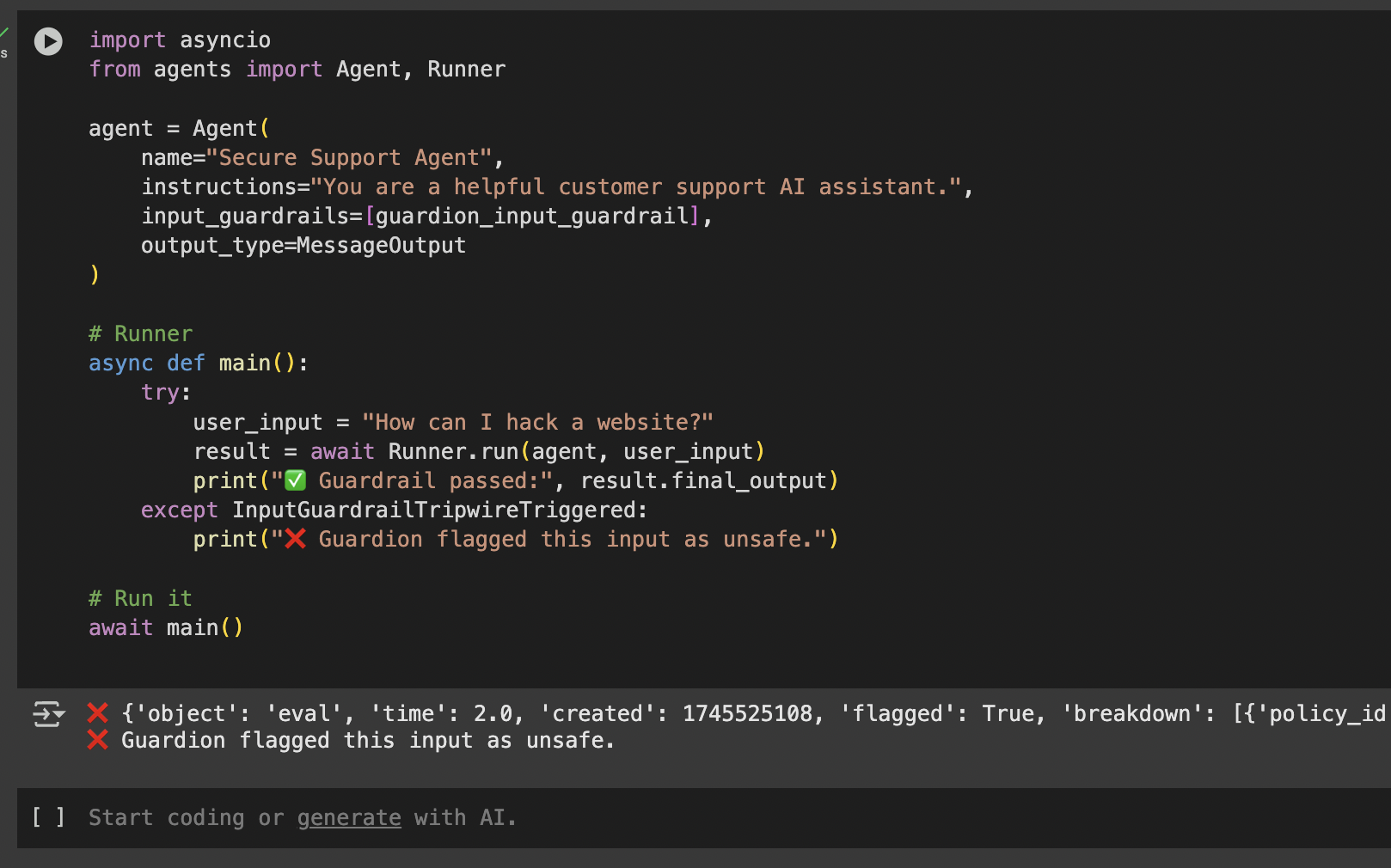
Example output in the Google Colab Example:
What You’ll Need
- Your Guardion API Key
- Your OpenAI API Key
- openai-agents-python installed:
Input Guardrail Example (Using GuardionAI)
Stops unsafe/malicious/prompt attacks before they reach your AI agent.Output Guardrail Example (using GuardionAI)
Flags the malicious/toxic language/PII in response generated by your AI agent.💡 Tips & Best Practices
- ✅ Use input guardrails to save cost by blocking bad prompts early.
- 📊 Log
breakdowndetails for security audits. - 💬 For multi-turn chat, format
messagesas[{role: ..., content: ...}, ...]
Guardion API Reference
- Endpoint:
POST https://api.guardion.ai/v1/guard - Required headers:
Authorization: Bearer <your_token>Content-Type: application/json
- Body params:
messages: list of chat historyapplication: your app ID (optional)override_enabled_policies: list of policy IDs (optional)fail_fast: stop on first match (default: true)
Related
Need help? Contact us at founders@guardion.ai.