The Advanced Prompt Attack Detection
Developed by industry experts with experience building enterprise-grade AI guardrails at Siri Apple, Nubank and other leading companies, ModernGuard is a specialized and modern transformer-encoder model designed to detect and prevent prompt attacks in real-time. This enterprise-grade solution offers multilingual support and ultra-fast inference capabilities to protect GenAI systems across various domains.
This is the model page for the Prompt Security detector. See the detector overview in Prompt Security.
Model Card
Modern Transformer-Encoder Architecture
- Built on ModernBERT, a high-efficiency encoder
- Features Rotary Positional Embeddings, Flash Attention, and memory optimizations
- Supports 8K token context with low latency
⚡ Ultra-Fast Inference
- Optimized for real-time streaming and in-line LLM applications
- Achieves sub ~50ms latency in production environments
Multilingual and Domain-Aware
- Trained on data in 8+ languages
- Covers banking, fintech, ecommerce, healthcare, and other verticals
🔐 Threat Intelligence Training + Continuous Updates
- Pretrained on 1 trillion tokens
- Fine-tuned on millions of simulated and real-world prompt attacks
- Proprietary red teaming data generated by AI attackers + red team partners
- AI threat databases & state-of-the-art prompt attack vectors
- Diverse synthetic data generation for safe examples
- Continuous updates with emerging threat patterns
Available Versions
- modern-guard-v1.5 — latest, recommended for production
- modern-guard-v1 — stable, production-proven
- modern-guard-v0 — initial release
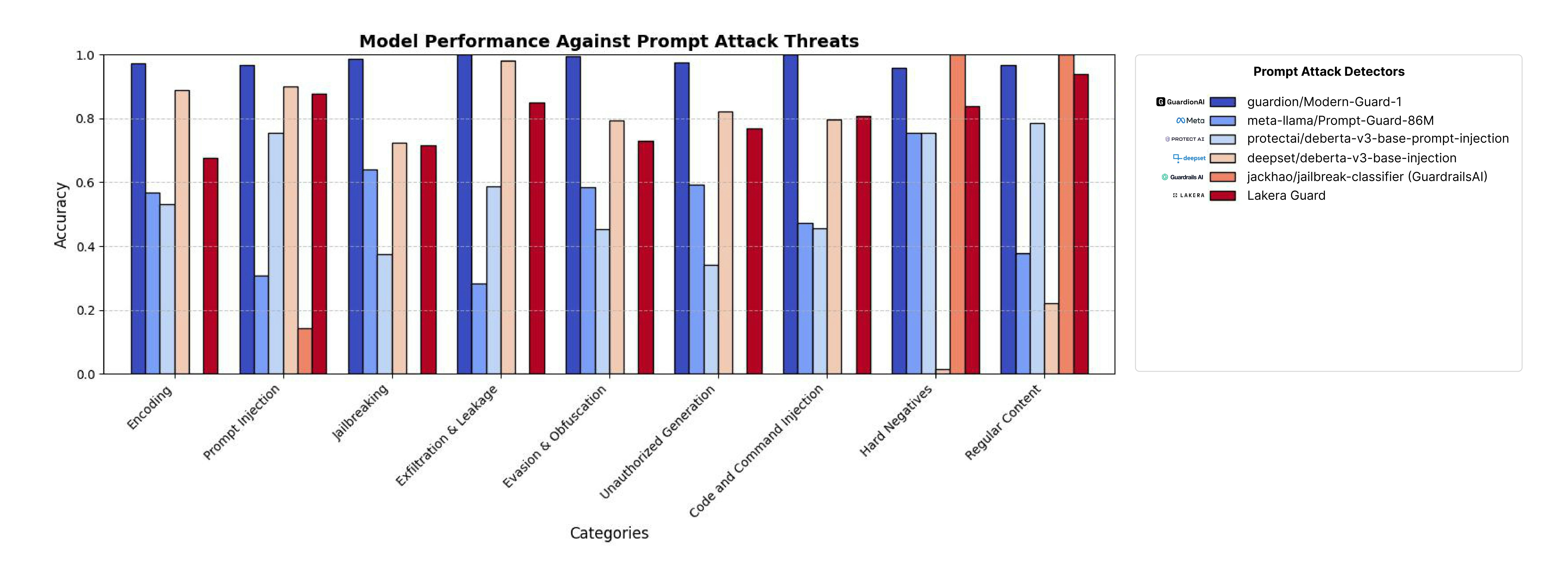
Benchmark Results
This is the result for the benchmark, collecting public and private threats from red teaming partners and with set of updated threats database used from NVIDIA Garak and PromptFoo libraries. Our comprehensive evaluation demonstrates ModernGuard’s superior performance across diverse attack vectors. The benchmark methodology includes:- Evaluation against 40+ attack classes
- Cross-validation across multiple domains and languages
Overall F1-Scores
We missed any other prompt injection detector model or solution? Please, let us know, and we can add the evaluation as well.
Threat Category Coverage
How to Use ModernGuard
Combine ModernGuard with a guardrail policy, then evaluate with that policy.💡 Example integration
Related
- Injection — how to use ModernGuard models as a detector in policies